
Welke stappen neem je naar een succesvol Data Analytics platform?
Data wordt ook wel ‘het nieuwe goud’ genoemd. Het benutten van die data zorgt voor inzicht en voorspellend vermogen. Voor het uitnutten van data leveren cloud providers, zoals Google, Amazon en Microsoft, services waarmee je een Data Analytics platform bouwt.
Dit artikel beschrijft hoe je zo’n Data Analytics platform bouwt. Dit artikel is geschreven voor IT-beslissers en IT-experts die werken in het dataveld en zijn belast met het realiseren van AI-toepassingen in hun organisatie. De leestijd van dit artikel is ongeveer 5 minuten.

Auteur:
<Introductie>
CxO’s hebben de toegevoegde waarde van data ontdekt en potentie hiervan voor het bedrijf. Data wordt daarom ook wel het goud van de 21e eeuw genoemd. Het is daarom niet voor niets dat data analytics zo’n hoge vlucht neemt.
Data stores zijn echter nooit ontworpen en gebouwd om haar data op deze wijze uit te nutten. Hierdoor zit het spreekwoordelijke ‘goud’, 15 kilometer onder de grond. De data is niet beschikbaar voor gebruik. De vraag is dan ook: ‘wat is nodig om de data wel beschikbaar te krijgen voor de inzet van data analytics’.
Voor het beantwoorden van deze vraag bespreken we kort het Cross-industry standard process for data mining, ofwel het Crisp-dm model. In een eerder NISI artikel, ook gepubliceerd op AGConnect hebben we het Crisp-dm model uitgebreider beschreven.
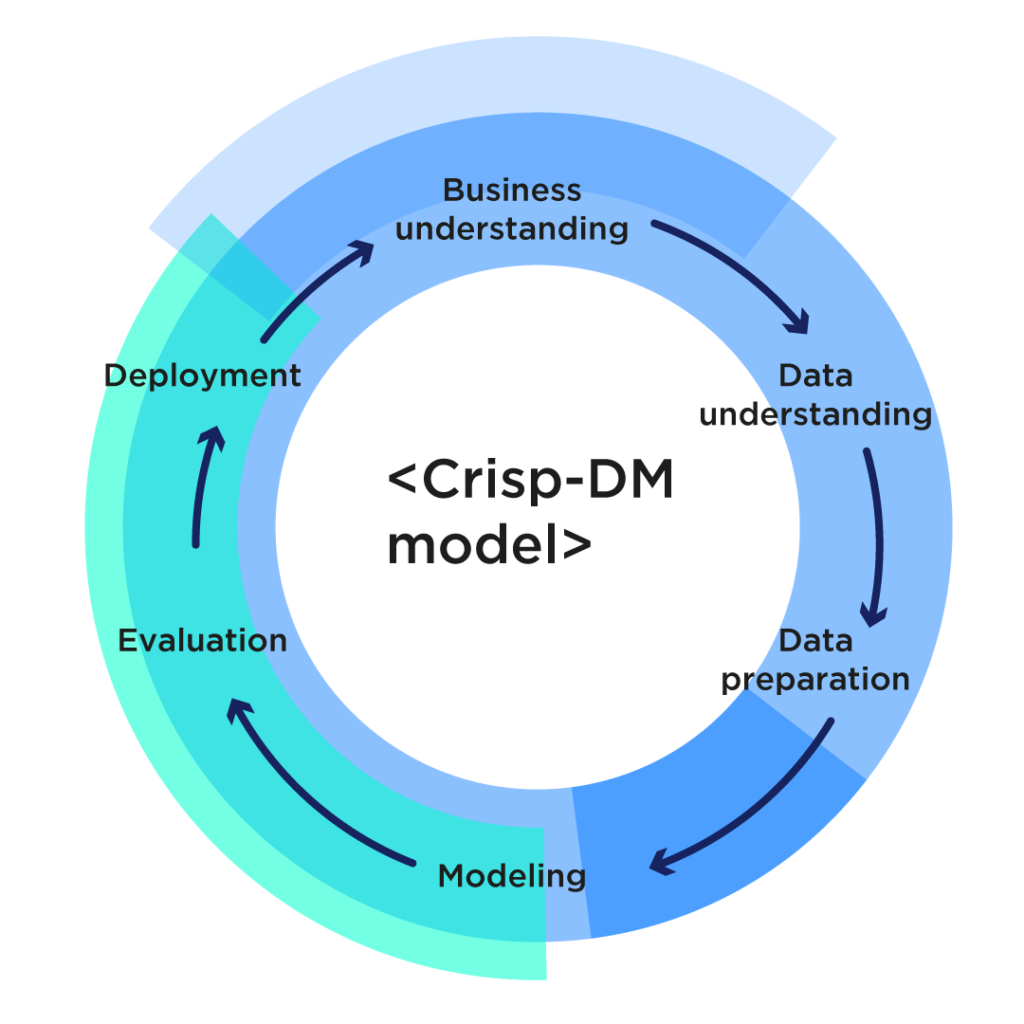
Het model bevat zes onderdelen:
- Business understanding: het bepalen van de behoefte van de business
- Data understanding: het beter begrijpen van de beschikbare data
- Data preparation: voorbereiden en opschonen van de data, zodat het geschikt is om modellen mee te bouwen
- Modeling: het bouwen van verklarende en/of voorspellende modellen
- Evaluation: het evalueren van het resultaat en voorgaande stappen herhalen
- Deployment: uitrollen van het model zodat het beheerst en herhaalbaar kan worden uitgerold
<Een data analytics functie in de organisatie>
Het Crisp-dm model bevat dus zes onderdelen om te komen tot een data analytics functie. Het Crisp-dm model is een iteratief model. Dat wil zeggen dat je de cyclus vele malen doorloopt om te komen tot het gewenste data analytics model. In de eerste iteraties volstaat een kopie van de data of gebruik toegang tot een bestaande datawarehouse voor toegang tot de data. Na een aantal iteraties ontstaat de behoefte om een data analytics platform te realiseren. Het realiseren van een data lake op een schaalbaar cloud platform is dan de eerste behoefte. In het volgende deel van het artikel introduceren we de vijf services die deze behoefte afdekt.
<Vijf data analytics platform services>
Het concreet realiseren van zo’n data lake gebeurt met de services van cloud analytics providers. Deze vijf data analytics web services zijn:
- Data lakes
- Identity Access Management (IAM)
- Serverless Computing
- Data Transformations
- Infrastructure as Code
In het resterende deel van het artikel behandelen we elk van de vijf services. Voor de concreetheid van het artikel verwijzen we regelmatig naar services van Amazon en Microsoft.
<Data lakes>
Data storage betreft het vastleggen van informatie in een bewaarmedium, waaruit data gemakkelijk kan worden gehaald voor gebruik. Voor data storage leveren cloud providers services. Voor het bewaren van data levert Amazon bijvoorbeeld de Simple Storage Service (S3). Voor data engineers staat S3 centraal in het aanleggen en beheren van een data lake.
Data lakes zijn storage repositories die grote hoeveelheden raw data bevatten tot deze data nodig is. S3 levert vier storage classes, die elk een specifiek doel hebben. Het type bepaalt een data engineer op basis van levensduur en beschikbaarheid van de data. De vier classes zijn:
- Amazon S3 Standard, gebruikt voor veel gebruikte data
- Infrequent Access (IA), gebruikt voor backups en data recovery.
- One Zone-Infrequent Access, ontworpen om zelden-gebruikte data snel te benaderen
- Amazon Glacier; gebruikt voor data die lang -zeven tot tien jaar- bewaard blijft en waarbij een lange laadtijd acceptabel is.
<Identity Access Management (IAM)>
Organisaties bestaan uit stakeholders die elk toegang nodig hebben tot verscheidene datasets. Cloud providers leveren repositories om rechten zoals read-only en write te verlenen aan gebruikers. Het betreft CRUD (Create, Read, Update, Delete) rechten. Bijvoorbeeld developers hebben rechten om te schrijven, terwijl business owners alleen read-only toegang hebben tot databronnen. Microsoft Azure levert hiervoor Azure Active Directory. Azure Active Directory hanteert een RBAC achtige opzet, met de entiteiten:
- User, identity met een account
- Group, groep met users, deze heeft ook een identity
- Role, een user of groep identity toegewezen aan een rol in een scope
- Resource group, verzameling van resources toegewezen aan een bepaalde rol
- Resource, Azure resource, zoals b.v. een virtual machine of database
<Serverless Computing>
Serverless computing betreft het toewijzen van flexibele machine resources aan gebruikers. Één van de voordelen van serverless computing is dat een eigenaar van de resource alleen betaalt voor de tijd waarin de resource in gebruik is. Alleen betalen bij gebruik heet ‘pay-as-you-go’. Flexibel wil zeggen dat het systeem elastisch op- en afschaalt. Hierdoor zijn developers geen tijd kwijt aan het opzetten en finetunen van de cloud resources.
AWS biedt Lambda als serverless computing service. Met een Lambda service voer je code uit, zonder servers te hoeven managen. Het schaalt automatisch tot het niveau om te opereren. Ook Lambda is een pay-as-you-go service. Het kost niets als er geen code in runt. Lambda levert real-time monitoring en logging functies om inzicht te houden in het gebruik en de kostenontwikkeling.
<Data Transformations (ETL)>
Data engineers halen data uit een bronsysteem, waarna de data een validatieproces doorloopt. Na de validatie doorloopt de data een transformatieproces, waarna het proces de data wegschrijft naar een doellocatie. Dit is de essentie van Extraction, Transformation and Load (ETL).
Een veelgebruikte service om ETL scripts in te schrijven is AWS Glue. Met Glue bouwen data engineers event-driven ETL pipelines. Dit houdt in dat Glue een script uitvoert zodra er nieuwe data binnenkomt op een bronlocatie. Een groot voordeel van Glue is dat verschillende stakeholders binnen een organisatie de mogelijkheid hebben data te bewerken. Het biedt zowel visuele als op code gebaseerde interfaces. Daarbij bevat Glue integraties met PySpark, waardoor de service ook geheugen-intensieve data transformaties toepast.
<Infrastructure as Code>
Infrastructure as code (IaC) is het managen van cloud resources door het gebruik van templates als onderdeel van Continuous Deployment. Deze templates zijn te lezen door zowel mens als machine. IaC heeft drie belangrijke voordelen:
- Een template zorgt voor duidelijkheid welke resources onder een account runnen, en welke instellingen ze hebben.
- Infrastructure as code voorkomt fouten door verkeerde instellingen en per ongeluk verwijderen van resources.
- Hergebruik van code voor het verhogen van horizontale schaalbaarheid. De code dient als basis voor meerdere services.
Azure levert native ondersteuning for IaC met de Azure Resource Manager. Ontwikkelaars bouwen declaratieve templates die de infrastructure specificeren voor het uitrollen van hun software. Voor complexere taken is Terraform, Ansible of Chef een optie.
AWS biedt CloudFormation als oplossing. Cloudformation toetst of de resources die met IaC zijn gecreëerd stabiel blijven. Het verifieert of het opstarten en stabiliseren goed verloopt. Indien dit niet het geval is, rolt CloudFormation de resources terug naar een eerdere stabiele state. Naast CloudFormation bevat AWS een Cloud Development Kit (CDK). Het is een software development framework voor het definiëren van cloud IaC. Via zogenaamde CDK constructs is het mogelijk om infrastructuur eenvoudig te hergebruiken.
Met Continuous Delivery pipelines integreren we gemaakte infrastructuur in de (virtuele) IT infrastructuur. Het biedt de mogelijkheid om meerdere identieke omgevingen op te zetten.
<Samenvatting>
In dit artikel hebben we het Crisp-dm kort behandeld met de zes onderdelen en hoe je dit met Azure en Amazon Web Services (AWS) operationaliseert. Als je met behulp van dit artikel een data analytics platform opzet heb je de basis gelegd voor de realisatie van je AI-modellen.
We komen graag met je in contact om inhoudelijke gesprekken te voeren over innovatie en data en cloud. Indien je meer wilt weten over deze onderwerpen neem dan contact op met Wiconic, 030-268 53 98.
<Over de Auteur>
Dit artikel is geschreven door data engineer Kouros Pechlivanidis en lead Data Engineering Fabian Langer. In december van 2019 is Kouros gestart bij Wiconic. Tijdens een traineeship heeft hij geleerd om kwalitatieve software te ontwikkelen in een wendbare ontwikkelomgeving. Het is zijn missie om de Nederlandse software-industrie te helpen door ideeën om te zetten in geïmplementeerde software oplossingen. Bedrijven bezitten tegenwoordig over grote hoeveelheden data gegenereerd uit verschillende bronnen. Als Young Professional in het gebied van Data Solutions helpt hij bedrijven deze data optimaal te benutten.