Build Lakehouses with Delta Lakes
<Waarom een Delta Lake de toekomst is van moderne dataopslag>
Bedrijven zijn in toenemende mate datagedreven organisaties met grote hoeveelheden data. Er zijn verschillende manieren om deze data op te slaan. In dit artikel beschrijven we de evolutie van dataopslag, van Datawarehouses tot Lakehouses.
Van datawarehouses, naar datalakes en lakehouses als de nieuwste oplossing. In het artikel maken we duidelijk dat er grote nadelen kleven aan datawarehouses en datalakes. Vervolgens laten we zien dat een lakehouse architectuur een betere mogelijke oplossing is voor dataverwerking.

Auteur:
<In den beginne: het datawarehouse>
Een datawarehouse is een centraal opslagsysteem voor gestructureerde data binnen een bedrijf. Hierin kan data vanuit verschillende bronnen toegankelijk gemaakt worden voor analyse en rapportage. De data is gecategoriseerd op onderwerp, waardoor gebruikers snel de relevante informatie vinden.
Een datawarehouse bestaat uit een aantal lagen. De eerste laag betreft de landing zone voor opslag van ruwe data.
Vanuit deze opslag wordt de data opgeschoond en gestandaardiseerd en opgeslagen in tabellen in de 2e laag: de integratie laag.Voor het opschonen en standaardiseren gebruik je tabelschema’s.
Data die in de integratielaag is opgeslagen beantwoordt nog geen business vraag. Hiervoor gebruiken we de de transitie van de data naar de derde laag: de presentatielaag. Data van verschillende integratietabellen combineren we tot één tabel voor elke vraag van de ‘klant’.

<Nadelen datawarehouse>
Het data warehouse geeft een goed overzicht van data binnen een organisatie.
Toch er zijn ook een aantal grote beperkingen met datawarehouses in onze datagedreven wereld:
– Ongestructureerde data, zoals afbeeldingen of audio kan je alleen opslaan als blob-storage.
– Een datawarehouse is ongeschikt voor Machine Learning.
– Datawarehouses zijn ongeschikt voor grote hoeveelheid data.
– Datawarehouses schalen slecht (wel scale up, geen scale out).
<Next step, the cloud: het datalake>
Om “big data” te ondersteunen is het datalake ontstaan. Een datalake is niet afhankelijk van database-software en -hardware. Immers datalakes gebruiken cloudopslag om data in alle vormen en maten op te slaan. Losse opslag is goedkoop, dus de ruwe data opslaan als blobs in cloud storage is een goede volgende stap in dataopslag.
Een datalake slaat grote hoeveelheden aan data, zowel gestructureerd als ongestructureerd op. De data sla je in zijn originele vorm op, in plaats van het te integreren en te verrijken, zoals in datawarehouses. Datalakes maken volop gebruik van cloud resources, zodat ze makkelijk en voordelig op schalen.
Niettemin hebben ook datalakes grote beperkingen:
– Met een grote bak aan data waar je alles in kan plaatsen, raak je snel het overzicht kwijt.
– Datakwaliteit is niet gewaarborgd.
– Datahistorie ontbreekt.
– Transacties op dezelfde data leidt tot datacorruptie.
<The Latest Step: Het Lakehouse>
Een Lakehouse combineert de voordelen van een datawarehouse en een datalake. Hierbij combineren we de technologieen van beide oplossingen om te komen tot een Lakehouse architectuur.

De data sla je net als bij datawarehouses centraal op en categoriseer je op onderwerp. Zo vinden gebruikers snel de benodigde data. Daarnaast slaat het zoals bij datalakes grote hoeveelheden data gestructureerd als ongestructureerd op. De onderliggende opslag is cloud storage, zodat opschalen makkelijk en voordelig is.
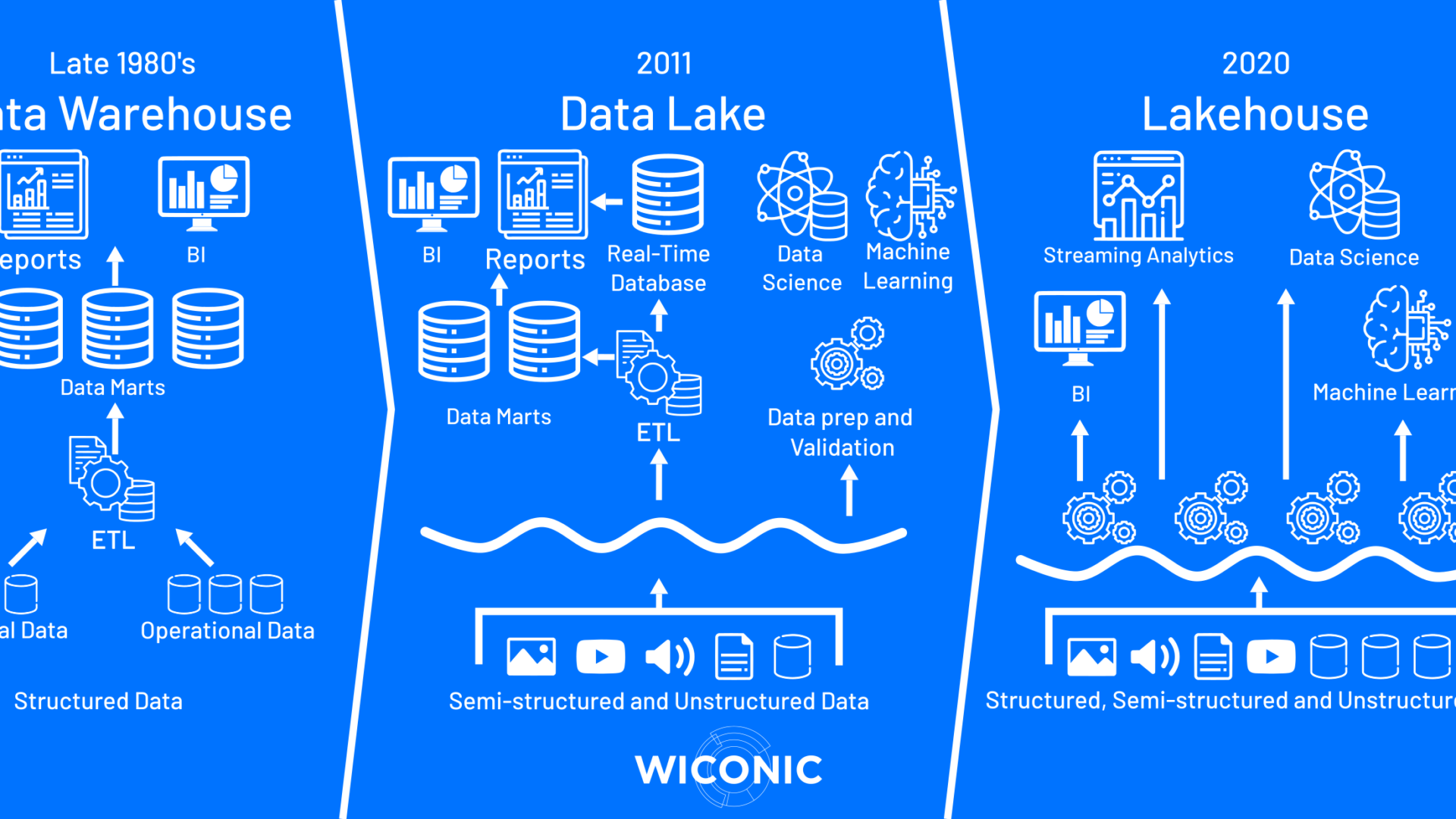
Hiernaast zie je grafisch van links naar rechts het overzicht van een datawarehouse, datalake en lakehouse met de bijbehorende technologie.
<Implementatie: Databricks Delta Lake>
Databricks is een dataplatform-service van een cloudaanbieder. Deze cloudaanbieders bieden het lakehouse aan in de vorm van een Delta Lake.
Een Delta Lake heeft de volgende voordelen:
- Je behoudt de structuur en het schemaoverzicht van een datawarehouse
- Je hebt de scalability van een datalake
- Je hebt support voor ongestructureerde data
- Je hebt ingebouwde historie over je data
- De data wordt heel efficient opgeslagen
<Opslag van data in een Deltalake>
Het Delta Lake slaat data op in het Parquet formaat. Dit open-source formaat is gemaakt voor het efficiënt opslaan en behandelen van grote hoeveelheden data. De datatype die je kunt opslaan varieren van tabel data tot multimedia.
Het Parquet formaat houdt een transactielog bij voor het bijhouden van de datahistorie. Als laatste garandeert het transactielog dat alle data aanpassingen niet tot corruptie van de data leiden.
<Medaille architectuur>
Naast een goed dataformaat moet de data ook goed gestructureerd worden. Hiervoor hanteert het Delta Lake een medaille architectuur, zoals de lagenstructuur van het datawarehouse. Data in het Delta Lake sla je op in drie promotielagen, waarbij data promoveert van brons, naar zilver, tot goud.
Bronzen data in een medaille architectuur
De Bronzen laag bevat de de ruwe data. Het schema van de data is (nog) niet bekend. De data bevat alleen metadata, zoals de ‘Ingest timestamp’. De Ingest time betreft het tijdstip van het importeren van de brondata. Het bewaren van de data (in de bronzen laag) is cruciaal omdat dat je brondata betreft. Met de Ingest time selecteer je in je ETL-proces het timestamp, waardoor je de rapportages kunt genereren voor elk moment in de tijd.
De data in de bronzen laag is ook erg geschikt voor Machine Learning doeleinden.
Zilveren data in een medaille architectuur
Data uit de Bronzen laag is niet direct geschikt om te gebruiken. Bijvoorbeeld om dat de data in deze laag duplicates bevat, of tabelkolommen een onjuiste datatype hebben. Daarom schonen we eerst de data op waarna we het opslaan in deze Zilveren laag.
Gouden data in een medaille architectuur
De laatste laag is Goud, de presentatie laag. In deze laag combineer je meerdere data tabellen uit de zilveren laag tot een presentabel resultaat.
<Samenvattend>
In dit artikel hebben we uitgelegd hoe je de voordelen van een dataware house en een datalake combineert in de Databricks implementatie: Het Deltalake. Met het Deltalake zorg je dat je voor data die geschikt is voor Machine Learning en AI-modellen. Wil je ook gebruik maken van een Deltalake en je data als ‘het nieuwe’ goud uitnutten. Neem dan contact met ons op, of bezoek een van onze TechCafe’s.